
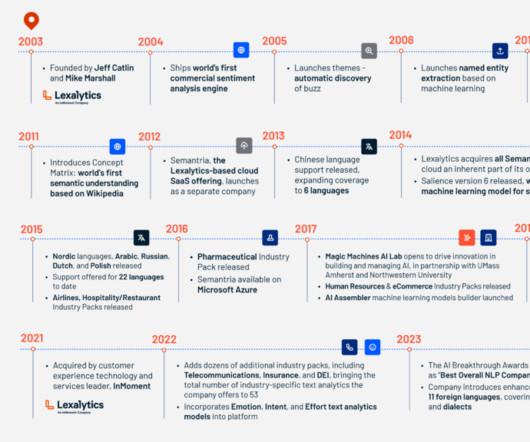
Lexalytics Celebrates Its Anniversary: 20 Years of NLP Innovation
Lexalytics
JULY 12, 2023
We’ve pioneered a number of industry firsts, including the first commercial sentiment analysis engine, the first Twitter/microblog-specific text analytics in 2010, the first semantic understanding based on Wikipedia in 2011, and the first unsupervised machine learning model for syntax analysis in 2014.












Let's personalize your content