This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
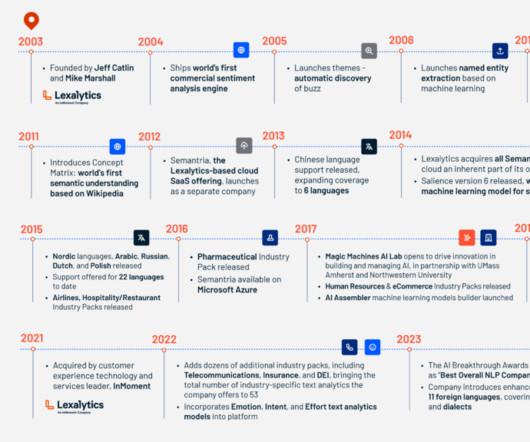
We’ve pioneered a number of industry firsts, including the first commercial sentiment analysis engine, the first Twitter/microblog-specific text analytics in 2010, the first semantic understanding based on Wikipedia in 2011, and the first unsupervised machine learning model for syntax analysis in 2014.
BioBERT and similar BERT-based NER models are trained and fine-tuned using a biomedical corpus (or dataset) such as NCBI Disease, BC5CDR, or Species-800. Data formats for inputting data into NER models typically include Pandas DataFrame or text files in CoNLL format (ie. a text file with one word per line). This study by Bui et al.
Transformer models like BERT , which are pre-trained on large quantities of text, are the go-to approach these days for embedding text in a semantic space. These vectors are then used either to find similar documents or as features in a computationally cheap model. A variety of such embedding models are available for users to choose from.
Google and Amazon were still atop their respective hills of web search and ecommerce in 2010, and Meta’s growth was still accelerating, but it was hard to miss that internet growth had begun to slow. It was certainly obvious to outsiders how disruptive BERT could be to Google Search. The market was maturing.
Ignore the plateau around 2010: this is probably an artifact of the incompleteness of the MAG dump.) The base model of BERT [ 103 ] had 12 (!) And what’s more, Google made BERT publicly available, so that everyone could have access to contextual word vectors. BERT is just too good not to use.
Reading Comprehension assumes a gold paragraph is provided Standard approaches for reading comprehension build on pre-trained models such as BERT. Using BERT for reading comprehension involves fine-tuning it to predict a) whether a question is answerable and b) whether each token is the start and end of an answer span.
From 2010 onwards, other PBAs have started becoming available to consumers, such as AWS Trainium , Google’s TPU , and Graphcore’s IPU. For the first instance type, they ran fine-tuning for the BERT Large model on the full Yelp review dataset, using the BF16 data format with the maximum sequence length supported by the model (512).
If you want to check out the new v3 features from spaCy, check out their blog post here: [link] Large Database of 90M Indian Legal Cases “Development Data Lab has processed and de-identified legal case records for all lower courts in India filed between 2010–2018, using the government’s online case-management portal — E-courts. torch==1.2.0…
If you want to check out the new v3 features from spaCy, check out their blog post here: [link] Large Database of 90M Indian Legal Cases “Development Data Lab has processed and de-identified legal case records for all lower courts in India filed between 2010–2018, using the government’s online case-management portal — E-courts. torch==1.2.0…
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














Let's personalize your content